새로운 강의는 이제 https://memi.dev 에서 진행합니다.
memi가 Vue & Firebase로 직접 만든 새로운 사이트를 소개합니다.
Mongo Sharding 1 - shard 구성
데이터량이 증가하고 접속자 수가 많아질 때 관리자는 시스템 업그레이드를 고려한다.
고사양으로 전환하면서 용량을 증가시키는데 이러한 것을 scale-up 이라고 한다.
서비스에 맞는 철저한 계획으로 고사양 서버를 선정한 후 증설시에는 더 많은 비용이 발생할 수 있다..
시스템 사양을 올릴때 일반적으로 전원을 셧다운하고 해야하기 때문에 서비스의 연속성면에서도 좋지가 않다.
mongodb 제작사인 10gen은 이러한 방식이 20세기형(1970~2000)이라고 설명하고 있다.
대용량 데이터를 탄력적으로 운영하기 위해서는 수평확장을 해야한다.
서버가 운영되다가 부하,용량이 늘어날때 서버를 N대 더 설치해서 분산해서 데이터를 쌓는 것이다.
반대의 경우 수평축소도 가능하기 때문에 탄력적인 비용으로 구성이 가능하다.
이것을 scale-out 이라고 한다.
KT Cloud Server를 3대 추가하여 수평확장이 되는지 검증해보도록 하겠다.
amazon aws ec2를 이용하고 싶지만 과금문제가 복잡해서 우선 KT로
준비
기본적으로 알아야할 사항은 공식 홈페이지를 확인한다.
https://docs.mongodb.com/manual/sharding/
실제 권장하는 서버를 운영할때 필요한 물리 서버는 최소 8대지만 대규모 서버도 아니고 해서….
그밖에는 아래 링크를 참조하자.
9대링크 : http://codingmiles.com/mongodb-sharded-cluster-deployment/
참조한 Post : http://haru.kafra.kr/33
물리서버 3대에 각 용도별 3대의 데몬을 띄울 것이다.
왜 굳이 3대일까? 공식사이트에선 1~3대의 configsvr를 구성하라고해서
1개의 configsvr를 구성하려고 이것저것 세팅해봤는데 3대를 권장하는 워닝이 찜찜했다.. 결론은 3대 권장
필요한 서버
- CentOS 7 Linux Server X 3
- config server X 3
- shard server X 3
- router server X 3
다양한 구성방법이 있지만 현재 필요한 용도로는 각 서버당 3개의 서버데몬이 다 올라가 있어야한다
보통 라우터는 한대만 놓지만 상위단에서 부하를 분할해야할 수도 있기 때문이다
간단한 개념은 사용자는 Router에 접속하여 config에서 정보를 얻고 shard에서 데이터를 r/w한다고 생각하면 된다
사용
Server
1. host 확인
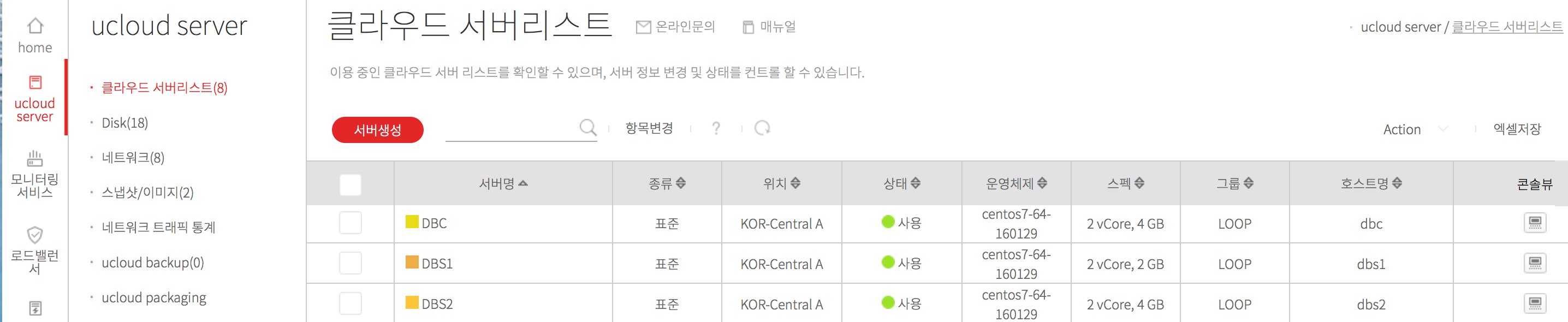
host 이름이 중요한데 각각 이렇게 정의했다
- dbc : db center
- dbs1 : db shard #1
- dbs2 : db shard #2
KT Cloud에서는 서버 생성시 호스트명을 선택할 수 있으며, 일반적인 경우에는 host파일을 수정하여 작업하면된다.
cloud server를 이용하면 마음껏 초기화, 제거 생성이 되서 테스트하기 편하다. 시간당 백원정도의 사용료가 들지만…
이 테스트를 진행하며 시행착오로 서버를 한 50번은 재생성한 것 같다
현재도 다 만들어 놓은거 3대 초기화하고 다시 정리하며 구성중 :(
세팅 후 1대가 수평확장이 되는지 테스트하기 위해 우선 2대만 세팅을 해보기로한다
dbc, dbs1에 ssh로 root로 접속후
각각의 서버에서 서로간에 핑을 날려서 호스트명이 잘 작동하는지 확인한다.
ping dhc
ping dbs1
귀찮게 호스트 네이밍 정해야하는 이유는.. 3.4부터 아이피로 세팅 자체가 안되게 변경된 것 같다. 사이트에가서 확인해보면 된다.
2. Update
각 서버에 인스톨 패키지를 최신화 시키자(선택사항임)

3. 저장공간 확보
KT Cloud의 경우 CentOS7으로 설치할 경우
20기가의 linux partition과 80기가의 빈 파티션이 주어진다.
당연히 데이터는 80기가의 파티션에 넣어야되기 때문에 포맷을 해야한다.
https://docs.mongodb.com/manual/administration/production-notes/
읽어보면 ext4, xfs 둘다 되지만 xfs format을 권장한다 하지만 KT Cloud여건상 ext4로 할 수 밖에 없었다..
mkdir /data //최상위에 마운트할 디렉토리 생성
fdisk -l //장치 목록 확인
fdisk /dev/xvdb //파티셔닝 n,p,엔터,엔터
mkfs.ext4 /dev/xvdb //포맷
ls -l /dev/disk/by-uuid //uuid확인 복사
vi /etc/fstab //시작시 자동마운트를 위해 편집기 실행
UUID=아까복사한아이디 /data ext4 defaults 1 2 //한 행 추가 저장
reboot //시작시 잘 마운트 되는지 확인
난 리눅스 전문가가 아니다 OS는 공부해야할 무언가가 아닌 편하게 쓰기 위한 시스템일 뿐이다.
개발자의 경우 비즈니스 로직이 잘 돌아가는 플랫폼이면 그만이다.
더 좋은 방법이 있으면 그것을 쓰면 된다.
4. DB install
각 서버에 아래 링크의 내용대로 mongo를 설치한다.
https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/
이런건 항상 공식사이트의 레퍼런스대로 하는게 좋다.. 괜히 한글 사이트 찾아서 쉽게 해보려다가 더 나락으로 떨어질 수 있다.
vi /etc/yum.repos.d/mongodb-org-3.4.repo //repo에 아래 내용 추가
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
yum install -y mongodb-org //설치
약 30초면 설치가 완료된다.
공식사이트대로 설치하고 나니 3.4.2가 깔린 것을 확인 할 수 있다
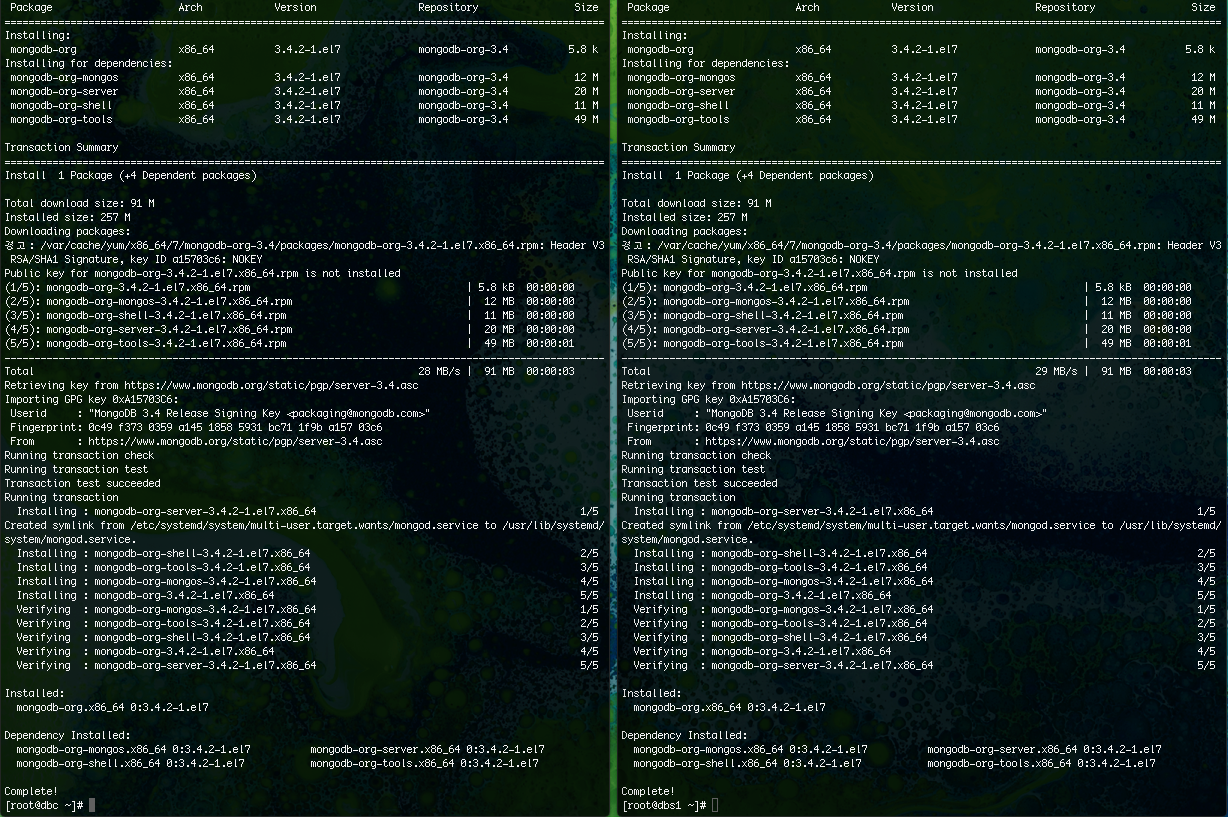
yum update에서 예외케이스를 넣어줘야 3.5로 실수 업데이트 되는 멘붕을 막을 수 있어서 관리적으로 좋지만..
보안 이슈도 있을 수 있으니 적응하는 편이 내 경우는 늘 좋았다.
5. mongo server 정상화
일반적으로 설치 후 # mongo를 치면 그냥 프롬프트(>) 가 뜨지만.. KT cloud에서는 워닝이 뜬다
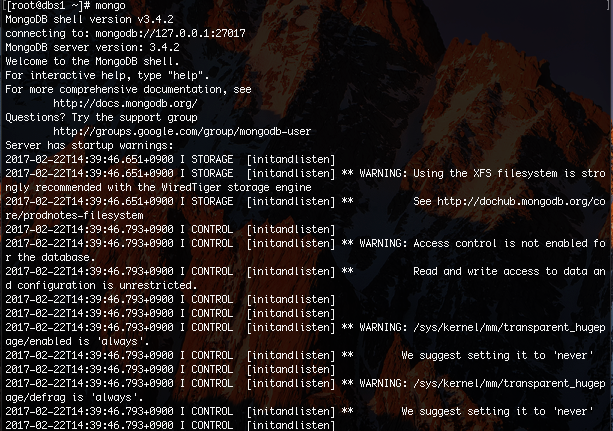
xfs는 내 잘못이 맞지만..
Transparent Huge Pages Warning을 아래의 링크대로 하면 소거할 수 있다.
https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
결론은 끄라는 얘기다
vi /etc/init.d/disable-transparent-hugepages //만들고 아래 내용을 붙혀넣는다
#!/bin/bash
### BEGIN INIT INFO
# Provides: disable-transparent-hugepages
# Required-Start: $local_fs
# Required-Stop:
# X-Start-Before: mongod mongodb-mms-automation-agent
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Disable Linux transparent huge pages
# Description: Disable Linux transparent huge pages, to improve
# database performance.
### END INIT INFO
case $1 in
start)
if [ -d /sys/kernel/mm/transparent_hugepage ]; then
thp_path=/sys/kernel/mm/transparent_hugepage
elif [ -d /sys/kernel/mm/redhat_transparent_hugepage ]; then
thp_path=/sys/kernel/mm/redhat_transparent_hugepage
else
return 0
fi
echo 'never' > ${thp_path}/enabled
echo 'never' > ${thp_path}/defrag
re='^[0-1]+$'
if [[ $(cat ${thp_path}/khugepaged/defrag) =~ $re ]]
then
# RHEL 7
echo 0 > ${thp_path}/khugepaged/defrag
else
# RHEL 6
echo 'no' > ${thp_path}/khugepaged/defrag
fi
unset re
unset thp_path
;;
esac
chmod 755 /etc/init.d/disable-transparent-hugepages //파일에 모든 권한을 준다
chkconfig --add disable-transparent-hugepages //시작프로세스 등록
reboot
mongo //warning 없어졌는지 확인
6. Firewall
위에 설정한 dbc와 dbs1은 핑은 잘 날라가지만 서로간에 디비 연결이 안됨을 확인 할수 있다..
아래 명령어는 같다. 생략 되어있을 뿐
[root@dbc~] # mongo
[root@dbc~] # mongo localhost
[root@dbc~] # mongo localhost:27017
[root@dbc~] # mongo dbc
두대의 몽고가 서로 접속이 되어야 하는데 아래와 같이 서로에게 접속해본다.
[root@dbc~] # mongo dbs1
[root@dbs1~] # mongo dbc
안되는 이유는 크게 두가지 이유가 있다.
- /etc/mongod.conf 에 자신만 접속하게 되어있다.
bindIp : 127.0.0.1을 0.0.0.0으로 변경하면 누구든 다들어온다. - 방화벽
일반 데스크탑버전 리눅스와는 달리 서버리눅스는 대부분 방화벽이 기본적으로 켜져있다.
KT Cloud에서 고맙게도 firewall-cmd을 enable 시켜놨고 ssh 빼고 다 막혀 있기 때문이다..
다 막혀있는 룰 덕분에 쓸 포트만 추가하고 리로드 하면된다.
MongoDB에서 기본값으로 잡아 놓은 포트는 아래와 같다
- router : 27017
- shard : 27018
- config : 27019
- webstatus : 28017
더 자세한건 아래 링크 참고
https://docs.mongodb.com/manual/reference/default-mongodb-port/
기본값, 즉 디폴트인 것일 뿐 권장사항이 아니다.. public port는 절대적으로 변경해야한다. 개발을 위해 또 다 막을 수는 없기 때문에 아이피 대역등으로 마스킹해야한다.(eg:x.x.x.0/24) 깔고나면 기본적으로 보안도 없어서 27017로 봇들이 들어와서 다 지우고 돈 요구한다..
초반에 누가 접속하겠어? 하는 안일한 생각으로 운영할때 다 털린 경험이 있다…
좋은 경험 덕분에 첫째도 보안, 둘째도 보안, N째도 보안 각성..
[슬픈 추억 스크린샷]
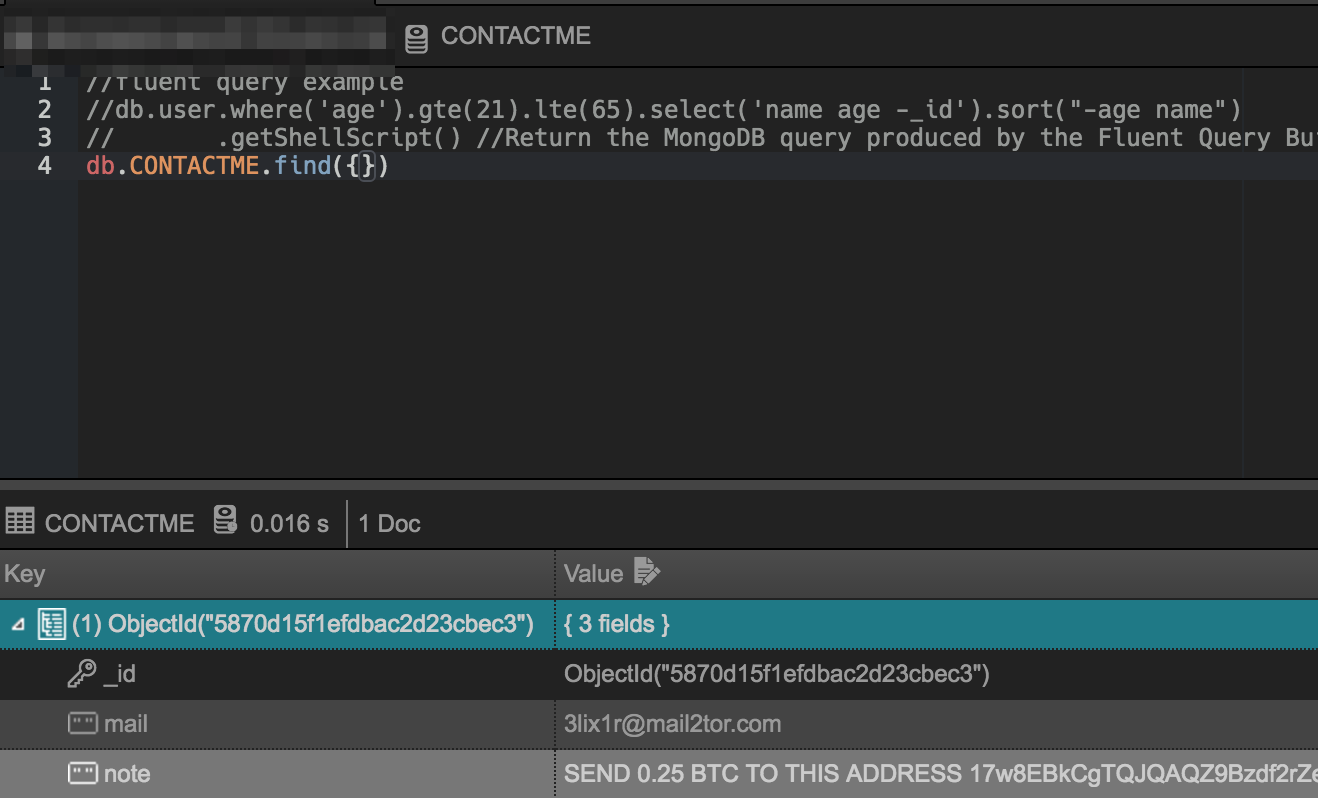
규칙 추가
[root@dbc~] # firewall-cmd --permanent --zone=public --add-port=27017/tcp
[root@dbc~] # firewall-cmd --permanent --zone=public --add-port=27018/tcp
[root@dbc~] # firewall-cmd --permanent --zone=public --add-port=27019/tcp
[root@dbc~] # firewall-cmd --reload
[root@dbc~] # firewall-cmd --list-all
7. Mongo server shutdown
위에 언급한대로 데몬을 새로 띄울 것이기 때문에 자동시작되는 기본서버를 꺼줘야한다.
systemctl disable mongod
reboot
9대의 서버라면 daemon이 아닌 각각의 /etc/mongo.conf 이것만 변경해서 systemctl restart mongod 하면 되지만…
한대의 서버에 3개의 mongo server를 구동해야되기 때문에 각 용도별 다른 포트로 실행시켜야한다.
8. Directory make
mongo계정을 만들어서 각 저장소를 준비한다.
root계정으로 mongo를 실행하면 되긴되는데 워닝이 뜬다.
mongo계정으로 모든 관련 기능을 수행하길 권장하는 문구가 뜬다.
그래서 mongo관련 데이터들을 mongo계정으로 만들어본다.
useradd mongo
passwd mongo //입력
mkdir /data/mongo
chown -R mongo. /data/mongo //mongo의 권한으로 하위항목을 모두 위임
ls -al /data //mongo 권한 확인
su - mongo //mongo로 접속
mkdir /data/mongo/db
mkdir /data/mongo/arbiter
mkdir /data/mongo/configsvr
mkdir /data/mongo/shardsvr
mkdir /data/mongo/log
mkdir /data/mongo/pid
9. Shard setting
기본적으로 들어 있는 conf file은 아래와 같이 작성되어있다.
https://ko.wikipedia.org/wiki/YAML 이라고 하는 데 마크다운과 비슷해 보인다.
# mongod.conf
# for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod.log
# Where and how to store data.
storage:
dbPath: /var/lib/mongo
journal:
enabled: true
# engine:
# mmapv1:
# wiredTiger:
# how the process runs
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod.pid # location of pidfile
# network interfaces
net:
port: 27017
bindIp: 127.0.0.1 # Listen to local interface only, comment to listen on all interfaces.
#security:
#operationProfiling:
#replication:
#sharding:
## Enterprise-Only Options
#auditLog:
#snmp:
이중에 #은 주석으로 안 쓰는 것이니 실제 쓰는 것 위주로 파일을 재생성 한다.
vi /data/mongo/shardsvr.conf
# shardsvr.conf
systemLog:
destination: file
logAppend: true
path: /data/mongo/log/shardsvr.log
storage:
dbPath: /data/mongo/shardsvr
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongo/pid/shardsvr.pid # location of pidfile
net:
port: 27018
# bindIp: 127.0.0.1 # Listen to local interface only, comment to listen on all interfaces.
replication:
replSetName: rs0
conf를 정리해보면
- 로그저장소 관련
- 데이터저장소 관련
- 백그라운드 실행 관련
- 네트워크 관련
- 복제 세트:https://docs.mongodb.com/manual/replication/ 구성(중요)
복제 세트는 기존에는 구성하지 않아도 되었지만 3.4부터는 필수로 넣어줘야함
각서버에 동일한 설정파일을 만들어서 아래와 같이 실행
mongod --shardsvr -f /data/mongo/shardsvr.conf //daemon이 위의 설정파일로 실행되었다.
ps -ef|grep mongo //프로세스를 확인해보면 포크된 번호와 일치한다.
샤드는 현재 상태에선 그냥 기본 서버와 크게 다르지 않다.
이제부터 복제세트, 즉 replica setting 을 해서 두 서버를 이어준다.
rs(replica setting)는 아래와 같은 method 있으니 참조하면 된다.
https://docs.mongodb.com/manual/reference/method/js-replication/
둘중에 한군데서만 해야하는데 dbc서버에서 설정해보겠다.
mongo localhost:27018
> rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "dbc.localdomain:27018",
"ok" : 1
}
rs0:SECONDARY> //이런 모양이됨
rs0:SECONDARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2017-02-22T07:29:36.537Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1487748571, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1487748571, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1487748571, 1),
"t" : NumberLong(1)
}
},
"members" : [
{
"_id" : 0,
"name" : "dbc.localdomain:27018",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 27,
"optime" : {
"ts" : Timestamp(1487748571, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2017-02-22T07:29:31Z"),
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1487748570, 2),
"electionDate" : ISODate("2017-02-22T07:29:30Z"),
"configVersion" : 1,
"self" : true
}
],
"ok" : 1
}
rs0:PRIMARY>
멤버가 하나 뿐인 복제셋이 완성되었다.
혼자이기 때문에 프라이머리이며 기본 서버처럼 읽고 쓰면 된다.
이제 멤버를 추가해보겠다.
rs0:PRIMARY> rs.add("dbs1:27018")
{ "ok" : 1 }
rs0:PRIMARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2017-02-22T07:37:14.876Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1487749021, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1487749026, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1487749026, 1),
"t" : NumberLong(1)
}
},
"members" : [
{
"_id" : 0,
"name" : "dbc.localdomain:27018",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 485,
"optime" : {
"ts" : Timestamp(1487749026, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2017-02-22T07:37:06Z"),
"electionTime" : Timestamp(1487748570, 2),
"electionDate" : ISODate("2017-02-22T07:29:30Z"),
"configVersion" : 2,
"self" : true
},
{
"_id" : 1,
"name" : "dbs1:27018",
"health" : 1,
"state" : 0,
"stateStr" : "STARTUP",
"uptime" : 8,
"optime" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"optimeDurable" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"optimeDurableDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2017-02-22T07:37:14.753Z"),
"lastHeartbeatRecv" : ISODate("1970-01-01T00:00:00Z"),
"pingMs" : NumberLong(0),
"configVersion" : -2
}
],
"ok" : 1
}
rs0:PRIMARY>
멤버가 추가된 것을 확인 할수 있는데 stateStr을 보면 dbc는 primary인데 dbs1은 startup이다..
primary, secondary 둘 이외는 정상이 아니라고 보면된다.
dbs1입장에서 “name” : “dbc.localdomain:27018” 로 연결을 못하기 때문이다.
dbs1입장에서는 “name” : “dbc:27018” 이 되어야 되기 때문이다…
최초 rs.initiate()에서 자동으로 들어간 “name” : “dbc.localdomain:27018” 때문에 접속이 안되는 것이다..
지나고보면 당연할 수도 있지만, 처음에 이것 때문에 정말 힘들었다…
그래서 rs.initiate([{},{}]) 이런식으로 멤버를 넣어서 초기화하는것을 추천한다
이상황에서 그럼 dbc만 바꿔보자.
rs0:SECONDARY> cfg = rs.conf()
rs0:SECONDARY> cfg.members[0].host = "dbc:27018"
rs0:SECONDARY> rs.reconfig(cfg,{force:true})
rs0:SECONDARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2017-02-22T07:43:42.138Z"),
"myState" : 2,
"term" : NumberLong(2),
"syncingTo" : "dbs1:27018",
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1487749419, 1),
"t" : NumberLong(2)
},
"appliedOpTime" : {
"ts" : Timestamp(1487749419, 1),
"t" : NumberLong(2)
},
"durableOpTime" : {
"ts" : Timestamp(1487749419, 1),
"t" : NumberLong(2)
}
},
"members" : [
{
"_id" : 0,
"name" : "dbc:27018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 873,
"optime" : {
"ts" : Timestamp(1487749419, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-02-22T07:43:39Z"),
"syncingTo" : "dbs1:27018",
"configVersion" : 72000,
"self" : true
},
{
"_id" : 1,
"name" : "dbs1:27018",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 385,
"optime" : {
"ts" : Timestamp(1487749419, 1),
"t" : NumberLong(2)
},
"optimeDurable" : {
"ts" : Timestamp(1487749419, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-02-22T07:43:39Z"),
"optimeDurableDate" : ISODate("2017-02-22T07:43:39Z"),
"lastHeartbeat" : ISODate("2017-02-22T07:43:40.486Z"),
"lastHeartbeatRecv" : ISODate("2017-02-22T07:43:40.667Z"),
"pingMs" : NumberLong(0),
"electionTime" : Timestamp(1487749408, 1),
"electionDate" : ISODate("2017-02-22T07:43:28Z"),
"configVersion" : 72000
}
],
"ok" : 1
}
rs0:SECONDARY>
이제 멤버들은 데이터를 복제해서 가지고 있다.
보면 dbc: secondary,dbs1: primary가 되어있다.
primary : read/write 가능
secondary : read만 선택적으로 가능(rs.slaveOk() 입력할 경우)
디비 작업을 하려면 프라이머리로 접속해야 하는 것이다.
그러면 primary, secondary는 누가 결정하나…
대략 공식사이트 내용을 보면 네트워크 상황, 핑등을 고려하여 vote(투표)로 결정한다고 되어있다.
rs.conf()로 내용을 확인해보면 priority라는 것이 기본값인 1로 설정되어있다.
이것을 높게 주면 우선권이 높아지지만 같은 사양 물리 서버에서는 권장하고 있지는 않는다
이제 dbc를 primary로 바꾸고 싶은데 어떻게 해야할까?
method로는 없다. dbs1을 reboot 시키면 dbc가 primary가 된다. 뭔가 방법은 있겠지만 공식사이트에서는 권장하지 않는다.
[primary change]
[mongo@dbs1 mongo]$ ps -ef|grep mongo
root 4198 2512 0 16:09 pts/0 00:00:00 su - mongo
mongo 4199 4198 0 16:09 pts/0 00:00:00 -bash
mongo 4610 1 0 16:19 ? 00:00:00 mongod --shardsvr -f /data/mongo/shardsvr.conf
mongo 4759 4199 0 16:22 pts/0 00:00:00 ps -ef
mongo 4760 4199 0 16:22 pts/0 00:00:00 grep --color=auto mongo
[mongo@dbs1 mongo]$ kill 4610
mongod --shardsvr -f /data/mongo/shardsvr.conf //재구동
rs0:SECONDARY> rs.status() //dbc에서 다시 확인
dbc에서 rs.status()를 계속 쳐보면 dbs1의 상태가 변하는 것이 확인된다.
둘다 secondary가 되었다가 몇분후 dbc가 다시 primary를 가져간다..
이제 데이터를 써보고 두대를 교대로 껏다켰다하면서 primary로 설정되어있는 db 에 연결해서 데이터가 온전한지 확인해 보면 된다.
rs0:PRIMARY> use test
switched to db test
rs0:PRIMARY> for(var i = 0; i < 100000; i++) db.trash.insert({n:i,d:"tt"})
실수로 root로 실행 하게 되면 root로 파일권한을 바꿔버리기 때문에 mongo계정으로는 실행이 안되는 현상이있다.
ERROR: child process failed, exited with error number 100
데이터 확인해보고 아래와 같이 해결하면 된다..
chown -R mongo. /data/mongo/shardsvr
crontab -e 로 자동화하려다 mongod가 fork 되지 않는다는 메세지가 뜨면서 영원히 실행이 안되서 당황한 적이 있다.
결론
여기까지 작업만해도 수평확장은 되는 셈이다.
하지만 primary가 누군지 알수 없기 때문에 configsvr, router를 통하지 않으면 백업용도 외에는 쓰기가 어렵다…
성능은 좋으나 설치가 까다롭고 자료가 너무 없다.
공식사이트에서 영문 매뉴얼 파야한다.
apm(apache php mysql) installer, wizard 같은 툴이 있으면 좋겠음..
node.js & npm 조합이 그리움…
점수 7점
의견
여기에는 기본포트를 쓰고 있지만 실제 서비스에서는 절대 기본포트를 쓰면 안된다.
물론 포트 변경가지고는 절대방어가 되지 않지만, 봇이 더 많은 포트 탐색을 하게 만드는 역활정도는 해준다.
실제로는 어플리케이션 서버(node.js + mongoose api)에서만 접속하게 방화벽 세팅을 해야한다.
공인 포트로는 들어갈 일이 없게 만들어야한다.
댓글남기기