새로운 강의는 이제 https://memi.dev 에서 진행합니다.
memi가 Vue & Firebase로 직접 만든 새로운 사이트를 소개합니다.
데이터베이스 사용 및 팁
저는 전산쪽과 1%도 상관이 없는 사람인데 어떠한 계기로 데이터베이스를 쓰게 되었습니다.
데이터베이스가 괜히 어렵고 시작하기 어려운 분들께 도움이 되었으면 합니다.
지식이 많지 않은 저같은 사람도 쓸 수 있을 만큼..
데이터베이스는 그저 편의를 위해 존재한 다는 것을 알려드리고 싶습니다.
그리고 조심해야할 점도…
실제 다른 방법으로 운영하는 분들의 의견도 들어보고 싶습니다..
데이터베이스를 시작하게된 계기
윈도우 프로그램을 시작할 무렵 할 수 있는 거라고는 파일 처리 뿐이었습니다.
주로 연구과제 성격의 로그데이터를 저장하고 읽는 일이었습니다.
매일 파일을 여러개 저장하는 것이라 저는 이렇게 처리 했습니다.
저장 위치: 년 / 월 / 일 / 차량번호_시작시분초_끝시분초.log
eg) 2011/08/22/서울12가3456_172255_191211.log
저장 위치를 리스팅해서 어떤 표에 그리고 클릭하면 차트도 나오고 약간의 분석도 나오는 그런 것들을 만들었죠..
혈기왕성 초심 가득한 개발자라 모든 요청은 들어오는 즉시 처리했습니다.
신경 안쓰고 1년이 지나니 파일이 만개도 넘어서 엄청나게 버벅인다고 연락이 옵니다.
그래서 선택상자를 만들어서 년월일을 고르면 리스팅이 되게 처리했습니다.
또 요청이 옵니다.
8월치만 날짜 거꾸로 정렬해달라고..
버블소트니 뭐니 공부해서 구현 완료…
또 요청이 옵니다.
차량번호 기준으로 정렬해달랍니다..
만개가 넘는 파일을 다 뒤져서 추출 후 정렬..
또 다른 요청..
해당 로그파일의 요약 값중 속도 평균 값만 정리된 표는 안되나요?
로그파일을 반복문으로 돌려서 요약 값을 만든 후 년 / 월 / 일 / 차량번호.calc 라는 말도 안되는 파일을 만듭니다.
또 요청..
현재까지 최고 속도는 어느 차량이죠?
해보니 뭔가 목차, 인덱스 같은 것이 필요할 것 같았습니다.
한번 전체 파일을 다 뒤져서 요약한 값들을 summary.info 라는 파일을 만들어서 저장해두었습니다.
이제 요약본이 있어서 빠르게 색인된 파일들 위치가 금새 나오게 되었습니다.
그런데 하다보니 뭔가 다른 것 필요할 것 같았습니다.
어디서 들어봤던 데이터베이스를 검색해보고 살펴보았습니다.
느꼈습니다.. 내가 했던 개고생을 다들 이렇게 쉽게 극복하고 있었구나…
그렇게 제가 시작했던 첫 데이터베이스는 MySQL이었습니다.
운영 문제
데이터베이스로 색인을 해두니 간소한 테이블 몇개로 데이터를 찾고 넣고 하는 것이 너무 부드러웠습니다.(행복함..)
문제는 서버 구축이었습니다.
지금 생각해보면 sqlite 같은 것이 적격이었을 텐데..
시작을 MySQL로 하는 바람에 서버를 구축하게 되었습니다.
그 서버는 바로 제 피씨였답니다..
제 피씨에 고정아이피를 주고 한참을 운영을 했는데요..
제 피씨는 늘 느리고 끄지도 못하는 피씨가 되었습니다.
몇달을 고생하다.. 그 핑계로 데이터베이스도 최적화되어있고 앱개발 가능한 iMac이 필요하다고 하여 말도 안되는 득템을 하게 됩니다.
그래서 클라우드 서버를 알아보기 시작했습니다.
제일 유명한 AWS를 알아보고 해봤지만 지식도 얕고 온통 영어인데다가 버지니아에 서버를 둬야하는 상황 같아서 패스하고 다른 것을 알아봤습니다.
그중 KT 클라우드를 선택하여 윈도우서버 2012에 mysql을 깔아서 운영하게 됩니다.
KT를 선택한 이유는 한글 메뉴가 전부였습니다.
리눅스
쓰는 거라곤 화면 필요 없는 MySQL 뿐인데 굳이 화려한 화면의 윈도우2012가 부적절해보였습니다.
리눅스서버보다 OS비용 2만원이 더 들거든요.. 약이 올랐습니다.
KT 클라우드에 리눅스서버를 한대 추가해서 MariaDB(MySQL과 거의 비슷함)을 구동 시키는데는 1시간도 안걸린 것 같습니다.
제가 생각한 OS(리눅스,윈도우)는 어플리케이션을 편하게 구동시켜주는 그 이상 그 이하도 아닌 것이 라고 늘 생각해 왔는데, 왠지 증명된 듯 하였습니다.
그러나 자주는 아니지만.. 글자를 수정하거나 하는 에디터(vi)같은 걸 써야될 때는 정말 고역이였습니다.
몇 일 해보면 할 만 하기도 해서..
vim 같은 걸로 코딩도 가능하겠는데? 라고 생각했다가.. 고수의 플레이를 보고..
저 길은 내가 절대 갈 수가 없는 길이구나… 라고 생각하고 접었습니다.
AWS RDS
생각해보니 내가 왜 리눅스 같은 걸 다뤄야하지? 누가 만들어주면 안되나? 라고 생각한 것이 이미 있었습니다.
바로 AWS(아마존이 운영하는 클라우드 서버) RDS 서비스인데 리눅스 운영 같은 거 상관 없이 그냥 읽고 쓰면(CRUD) 되는 획기적인 것입니다..
당장 가장 가까운 서버(도쿄였나?)에 뚫어서 돌려봤습니다.
리눅스 서버(ec2)도 몇개 만들고 NoSQL(DynamoDB)도 한번 만져보고 재미있게 놀았습니다.
몇개 되지도 않는 데이터인데.. 한달에 백만원이 넘었습니다.
얼른 연결된 카드 정지시키고 서버 꺼버렸습니다.
이유는 사실 지금도 잘 모릅니다. 과금 체계가 상당히 복잡한데 아마도 코드에 버그가 있지 않았을까? 하는 의심만 있고 귀찮아서 검증은 안했습니다.
대인배 아마존은 역시 사정을 얘기했더니 돈을 받지 않더군요..
하지만 앞으론 이런 걸 써야할 것이야.. 라는 확신은 가졌습니다..
개발자는 좀 더 생산적인 고민을 해야한다는 생각이 늘 있었으니까요..
NoSQL
RDBMS 운영중 고민했던 부분은 2가지였습니다.
- 날(raw) 데이터 처리
초데이터를 저장해야하는데 100대의 장비가 하루에 86400개의 데이터를 디비에 넣으니 역시 느리고 답답했습니다.
테이블도 일로 쪼개보고 장비별로도 다 쪼개보고 튜닝도 해봤지만, 정렬도 찾는 것도 정상이 아닌 것 같아서 파일로 저장했습니다.
그 파일들의 요약부분만 디비에 담아놨죠..
단일 서버에서는 상관 없지만 수평확장(scale-out)식의 서버에서 파일이란 것은 사실 엄청 불편한 것입니다.
부하에 따라서 서버를 복제해서 늘려야하는데 파일서버를 따로 둬야하는 번거로움이 있었거든요.
- 필드 추가
추가하는 것(alter) 자체는 어려운 일이 아닌데 이게 참 관리적으로 복잡했습니다..
테이블이 여러개일 때 짜증입니다.(구조를 잘못 설정한 이유가 더 크지만…)
혹시 이런 문제를 해소해줄 수 있나?(사실 구조만 잘 짜면 해결된다고 생각합니다…)
전에 해봤던 AWS DynamoDB가 생각나서 NoSQL을 찾아봤습니다.
그래서 찾은 것이 NoSQL계의 1인자 MongoDB..
MongoDB
리눅스 가상서버 하나 만들어서 바로 MongoDB를 깔아버렸습니다.
NoSQL 홀릭 그자체였습니다.
마침 자바스크립트(node.js) 많이 하던 때인데 데이터 자체가 자바스크립트 데이터(JSON)이라 행복했습니다.
요약데이터 몇개 설정 후 날 데이터 처리는 컬렉션(테이블) 하나 잡고 막 써버렸습니다.
게다가 규격에도 안맞는 데이터를 몽땅 넣어버렸습니다.
eg)
- 시간, 장비명, 유형, 거리, 속도
- 시간, 장비명, 유형, 길이, 높이, 파워
시간, 장비명, 유형에 색인을 걸어두면 다양한 장비를 유형별로 몇 억개의 데이터도 빠르게 검색이 가능했습니다.
문제는 두가지였습니다.
- 조인
조인이라 함은 요약된 정보와 매치되는 데이터들을 묶어 주는 것인데.. 이게 좀 한계가 있습니다.
여기 설명하긴 너무 길어져서.. (agregate, lookup등과의 차이) 접습니다..
사실 RDBMS가 너무 그리웠습니다..
그래서 색인은 RDBMS로 하고 날데이터만 NoSQL로 가볼까도 고민했습니다.
하지만 관리적으로 짜증나죠.. 혼자 다해야하는데..
- 용량
미친드시 늘어납니다.
사실 저렇게 날 데이터를 한 곳에 다 넣는 것은 미친 짓입니다.
적당히 분리해줘야죠..(파티셔닝)
리눅스 서버에 300기가 몇달만에 다 차갑니다.
안절부절.. 몽고디비 짱이라고 다 떠들고 다녔는데 혼날 것 같습니다…
MongoDB Sharding
서버를 늘려서 데이터를 나눠 가지는 시스템을 찾아봤습니다.
사실 이걸 알고 설치했어야 합니다. 이게 이들의 모토니까요(Scale-out)
100개의 데이터는 3개의 서버가 33(4)개씩 나눠 가집니다.
그리고 서버를 하나 늘리면 25개씩 나눠 가집니다.
그리하여 구현하게 됩니다.
까먹을까봐 정리도 나름 해놓습니다.
예전에 고민했던 흔적: 몽고디비 샤드 구성
만족스러웠습니다.
4대의 서버중 몇대를 세워도 멀쩡하고 데이터도 잘나눠가지고 늘어난다 싶으면 서버 한대(샤드) 한 대 더 추가하고..
그렇게 잘 운영하다 문제가 생깁니다.
몇십억개의 데이터가 쌓여서 이제 데이터를 좀 지워야했습니다.(과거 데이터는 별도로 아카이빙)
물리 하드 용량 90%즈음의 일입니다.
지웠는데도 불구하고 용량이 줄지 않습니다..
초긴장상태가 됩니다..
찾아보니 논리는 지운공간을 어짜피 다시 쓴다는 것입니다.(Wired Tiger)
논리대로라면 90%에서 멈춰야되는데 데이터가 왜 91%가 되고 있는 걸까..
당장 줄이는 방법(compact())을 알아봅니다.
서버 한대에 걸어놓은니 복구모드(Recovering) 상태가 됩니다.
약 2주의 시간이 지나고 정상(40%)이 되었습니다.
남은 2대도 이걸 하고 나니 6주가 걸렸습니다.
그 밖에도 자질 구레한 문제(StartUp2 상태에서 멈춤..등)에 봉착할 때마다 노이로제에 걸릴 것 같았습니다.
항상 중요한건 디비였으니까요..
운영을 너무 우습게 본 죄인 것이죠..(DBA분들이 있어야 되는 것입니다.)
도저히 참을 수가 없었기 때문에 대안을 모색합니다.
이제 돈이 문제가 아닙니다.
2가지를 고민 합니다.
AWS의 Dynamo, 아틀라스(MongoDB Atlas)
AWS는 아무래도 변환이 필요하니 아틀라스로 선택합니다.
MongoDB Atlas
아틀라스는 MongoDB에서 운영하는 클라우드 서비스입니다.
실제 서버는 AWS, GCP(Google꺼)둘 중 선택해서 사용합니다.
구글은 한국에 서버가 없어서 서울 리젼이 있는 AWS로 선택하였습니다.
결과는 대만족..
직관적으로 여러가지 차트로 상태도 볼 수 있고 확장도 클릭한번으로 해결되었습니다.(절대 몽고디비 직원 아닙니다.. 뽑아주지도 않겠죠..)
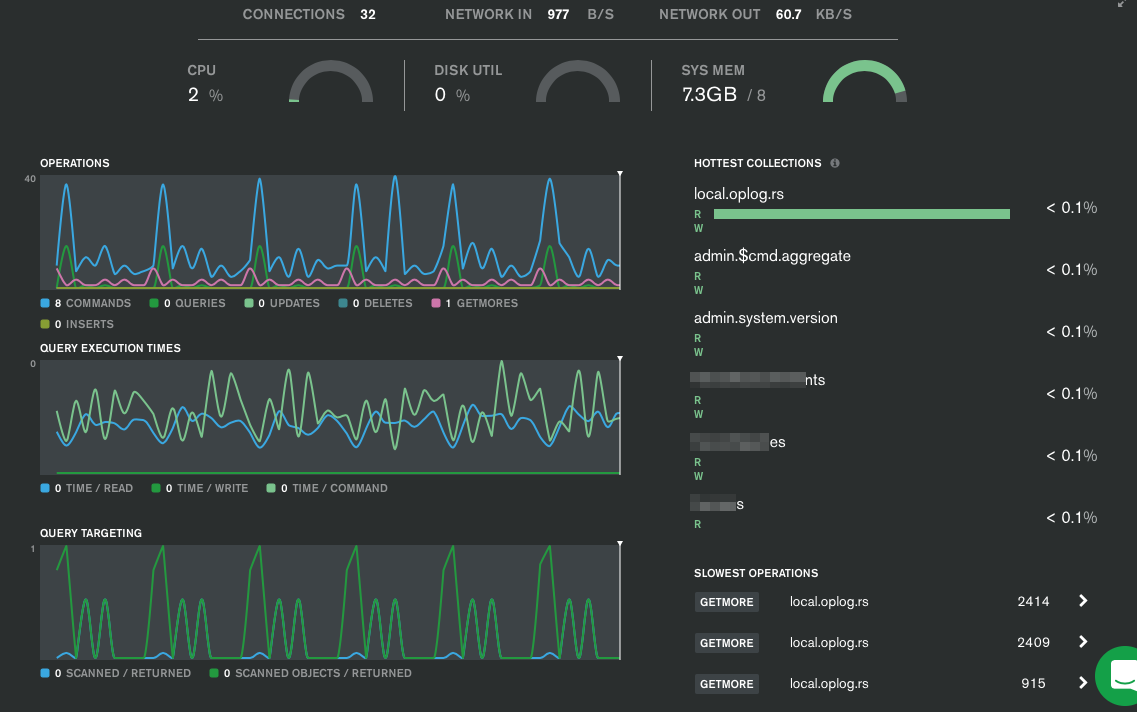
몇억개의 데이터도 꿀꺽 잘 삼키는 것도 확인했습니다.
자동확장(Auto Scaling)으로 40G에서 160G까지 늘어나는 것도 확인했습니다.
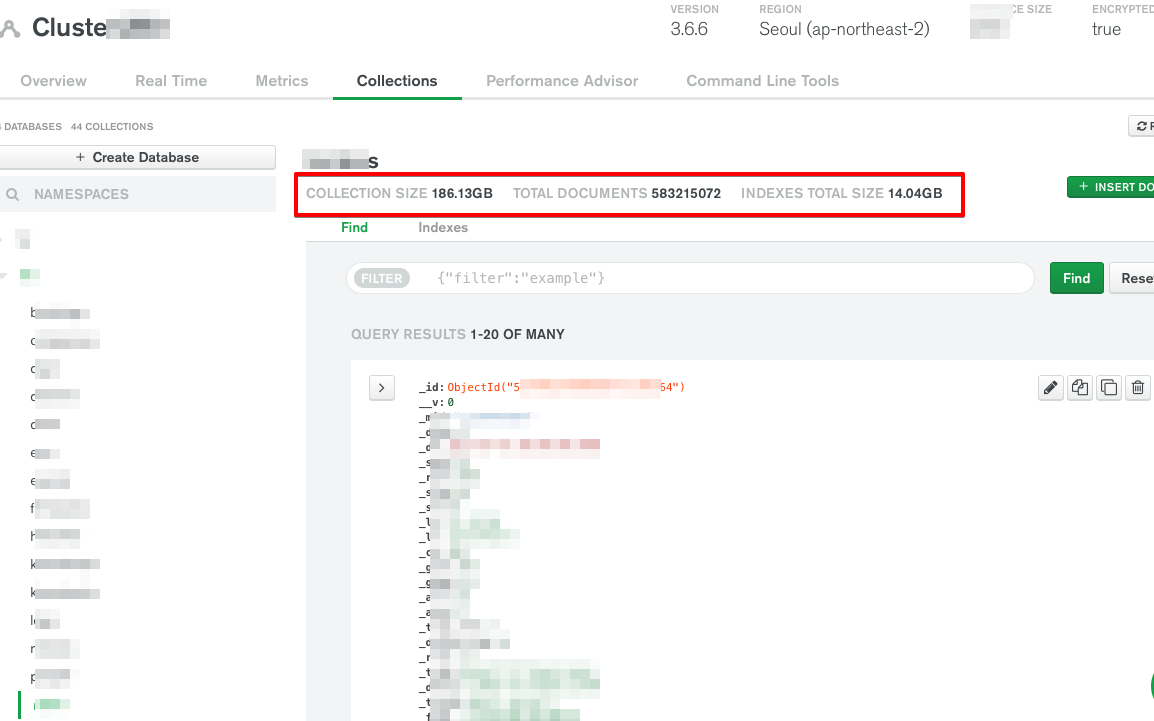
돈은 계산해보니 직접 운영하는 것 보다 15%정도 더 들지만, 이제 서버 노이로제는 좀 없어진 것 같습니다.
단점은 다 영어인게 문제인데.. 뭐 뻔히 데이터 읽고/쓰기만 하는데 전혀 지장 없습니다.
아직 구상중이지만 몽고디비 스티치(stitch)라는 것을 사용하면 백엔드 서버 조차 필요가 없게 됩니다.
어짜피 웹서버 돌려야되기 때문에 아직 크게 고민은 안하고 있지만..
프론트에서 디비까지 다이렉트로 읽고 쓰기가 됩니다.
구글 파이어베이스나 몽고디비 스티치 같은 행보를 보면.. 백엔드는 점점 더 필요 없어지는 것 같습니다.
백엔드를 정말 열심히해왔기 때문에.. 아쉽긴 하지만.. 이제 정말 프론트(React, Angular, Vue등) 중심 생산성의 시대가 오는 것 같습니다.
MongoDB Atlas 서비스
친절도 조사를 위해 한번 1:1채팅으로 문의를 넣어봤습니다.

영어를 잘 하지는 못하지만.. 대충 말 만들어서 보내봅니다.
일부러 데이터를 쌓아둔 후에 지워봤습니다.
그런데 하드 용량은 줄지 않은 이유에 대해 질문 해봤습니다.
- 질문:
Why is the data storage capacity still the same?
When will data storage be reduced?
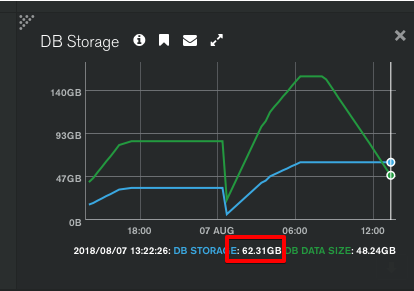
- 답변: 3시간 후에 옴(아마도 미국 시차 때문일 듯?)
Hi memi thank you for getting in touch.
In MongoDB, document deletion does not decrease the size of the DB storage size.
Atlas uses WiredTiger as the default storage engine and it will not release disk space created by deleting documents. However, following a checkpoint, WiredTiger will mark any space freed due to deletes or updates as being available for re-use. WiredTiger is a no-overwrite data engine, so when page items are updated/deleted, the page is eventually written into the file in a new location, and the block that holds the previous version of the page is made available for re-use. The WiredTiger block manager maintains a list of reusable blocks, sorted by size, and when new blocks need to be written, blocks available for reuse are checked and used before the file is extended.
Please feel free to reach out here if you have any further MongoDB Atlas questions.
대략: 와이어드 타이거가 어떤 블록을 지우면 그 공간을 바로 빈공간으로 만들지 않지만, 업데이트나 지운 블록에 대해서 와이어드 타이거가 바로 오버라이팅하는 엔진이 아니기 때문에 지워진 블록에 대해 다시 쓸수 있는 블록이라고 마킹을 해두고, 용량별로 소팅해 두었다가 새로운 블록을 쓰려고 할때 파일을 늘리지 않고 이공간을 다시 쓴다는 얘기인듯… 결국 와이어드 타이거가 용량관리를 해준다는 이야기인거 같음.. 단 맥락을 보면 데이터를 업데이트하면 바로 오버라이팅이 안되어서 일시적으로 용량이 늘어날 수는 있을 듯.
- 만족도 조사 메일
Help Mary understand how they’re doing:
Good!
- 결과
뭐 더 물어봐야겠지만. 일정 시간 후에 데이터 용량은 줄어 있었습니다.
그리고 매 자정마다 뭔 짓을 하는 지 줄어 있고요.
또 이것 저것 물어봐야겠죠~
결론
데이터베이스는 편하라고 있는 것입니다.
아무리 어려운 얘기 해봤자.. 여러가지 디비가 있어봤자..
쓰고, 읽고, 수정하고, 삭제하고(CRUD: Create Read Update Delete)가 전부입니다.
데이터의 양에 따라 구조와 운영은 완전 갈립니다.
만개 - 백만개 - 십억개 가 늘 때 서버 용량만 늘리는 것은 절대 해결책이 될 수 없습니다.
솔루션 자체를 달리가져가야 합니다.
같은 프로그램(외형)이지만 그냥 다른 프로젝트라고 생각하는 게 좋습니다.(만개짜리 프로젝트, 백억개짜리 프로젝트)
만개짜리 프로젝트라도 백억개짜리 프로젝트라고 생각하고 설계부터 확장성을 염두해두고 만드시면 좋습니다.(그런데 염두하다 시작도 못하니.. 적당히 해야합니다.)
구조가 제일 중요합니다.
색인 용량 늘린다고 빨라지진 않습니다.
나중되서 설계 바꾸기가 힘드니 처음에 많은 고려를 해야합니다.
DBA 없는 열악한 환경이라면 클라우드 서비스를 사용하세요..
괜히 돈 아끼다 돈 더듭니다..
커뮤니티 공개
클리앙 팁과강좌
댓글남기기